Troubleshooting Tips
And the Best Ping Tool is...

...not just a ping tool, and here’s why:
Ping — it’s one of, if not the most important and widely used network performance tests out there. It’s also the first place everyone goes when there’s a problem: “If my network’s busted, I need to ping it.”
So, when your connection turns to crap, what’s the best ping tool for the job?
That’s a bit of a trick question.
Ping’s a big deal, but it isn’t the whole story. Ping alone is rarely enough to get you the information you need to fix things. Thinking only about ping is one of the most common mistakes people make when it comes to monitoring or troubleshooting a network, no matter your experience level.
In most cases, you might think you’re looking for a ping tool, but you’re actually looking for something else — something that can tell you why your network is having issues.
There are more factors to network problems than just latency. Sticking only to ping won’t cut it, which is why finding a tool that does more is almost always the best choice.
Let us show you why.
Gettin’ ping-y with it
First, let’s get one thing straight: Ping kicks ass.
Ping is lightweight and efficient — the mark of any great tool. It uses (by default) a dedicated type of packet called ICMP, which, unlike other packet types, isn’t used to transport traditional data. Instead, it carries error messages and other control information between devices to communicate things like redirects and domain name requests. Since ICMP packets are so small, they don’t eat up bandwidth and are quickly exchanged, making them a great vehicle for simple things like, say, figuring out how long it takes to send a chunk of data to and from a location.
Another great thing about ping is how it originates from the host, providing the correct perspective on your network condition. A lot of web-based tools try to diagnose issues from the outside in, which can be wildly inaccurate. Ping sends test packets from the source: your device. The data you see is accurate and actionable.
As helpful as it is, ping isn’t perfect; far from it. For starters, pinging a server can tell you a lot, but it falls short for identifying the location of any issues en route. Consider the data ping actually collects. When you send an ICMP echo request packet to an endpoint, you learn two things:
- Whether your packet made it to its destination (or the response made it back to you).
- How long it took.
That’s it.
While knowing latency and packet loss frequency is useful in identifying the existence of a problem, that’s all it does. Ping is like a firefighter who just tells you your house is on fire — important information, but not very helpful for, you know, making things not on fire.
Another issue is tied to ICMP packets themselves and how some devices and firewalls handle your pinging. There's a lot to unpack with that, but here's the short version: Some routers and firewalls turn down or ignore ping packets to keep evil ne’er-do-wells from breaking stuff. Is it the sort of pitchfork mob-inducing issue people make it out to be online? Nah. But it is a thing ping struggles with.
It’s these shortcomings that make ping-only tools a hard sell. However, there is another option that addresses many of ping’s issues...sort of.
Traceroute does a lot, but...
If there is one network test as ubiquitous as ping, it’s traceroute. Traceroute provides more of the information you’re often looking for when trying to fix a problem, providing a better picture of a network by showing data on each hop between you and your target.
It’s hard not to see how traceroute makes for a more versatile and effective network testing option than ping. Finding the root cause of any network issue often means checking into each potential failure point. To do that with ping would require:
- Knowing the address of every device between you and your endpoint.
- Knowing exactly when dynamic routing causes a change in your route.
- Taking all the data you collect and comparing it to spot patterns.
You don’t have time for that — nobody does! Traceroute, on the other hand, uses a set of packets to essentially “feel out” every hop between you and your specified target. This creates both a list of devices and their corresponding latencies.
With traceroute results, you can actually see where the data from your ping test originated. Did latency suddenly triple four hops in? Do test packets never make it past your router? Traceroute tells you.
But traceroute isn’t perfect, either.
For starters, traceroute is slooooooooow. Because of how traceroute sends packets, it’s required to wait on the device (such as a router) at one hop to respond or timeout before sending to the next, and the more hops there are, the longer it takes.
This is compounded by another shortcoming: traceroute isn’t continuous. To do any real troubleshooting, let alone proactive network monitoring, you need to be testing constantly. Why? Because you’re unlikely to spot the real issue on the first try.
Imagine trying to take a picture of a lightning bolt. Unless you’re lucky (or the storm’s really bad), taking one random shot with your phone isn’t going to catch it.
To get an accurate picture of your network status, you need to continuously collect data.
Traceroute doesn’t do that, and even if it did, it would do it in a really unhelpful way. If you told traceroute to send a million packets, it’d just send a million packets to the first hop, wait for them all to come back, then send a million packets to hop two, etc. — like watching a ripple without seeing the pond. Going the other way, by sending only one packet to each hop and repeating, would just net you wildly inconsistent and relatively unusable data. Again, traceroute’s too slow.
But you know what isn’t slow? Ping.
And that’s where the actual best tool comes in.
PingPlotter: Unity. Precision. Perfection.
So, what’s the best network tool if it isn’t ping or traceroute? It’s both.
That’s what PingPlotter is: the combination of ping’s simple-and-delicious chocolate and traceroute’s salty-sweet peanut butter.
More accurately, PingPlotter leverages the strengths of ping to compensate for the shortcomings of traceroute. When you target an endpoint, PingPlotter maps the route just like traceroute, finding every device between you and the destination. Then, as PingPlotter finds each hop, it starts sending ICMP packets to continuously ping them.
PingPlotter is automatically conducting the sort of large-scale, real-time ping testing you’d be insane to attempt by hand, and it can do it for hundreds of targets without negatively impacting web traffic — and this isn’t even its final form.
There’s one extra component of network testing we haven’t touched yet, and it’s something PingPlotter does better than either tool we’ve mentioned: capture change over time.
As we said before, if network issues were consistent, predictable things, traceroute would be the perfect tool. But they’re not; conditions change and problems fluctuate. If your connection drops for 30 seconds every hour, that’s a huge deal. It’s also something other tools struggle to capture effectively.
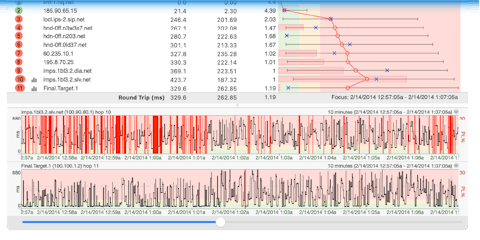
PingPlotter aggregates the raw data it collects and places it into scalable time series graphs. You can see network conditions before, during, and after an incident, be it seconds, hours, or even weeks. These graphs also visualize all the numerical data you would normally collect from ping and traceroute (and a few other important metrics ping and traceroute can’t get). Take this example:
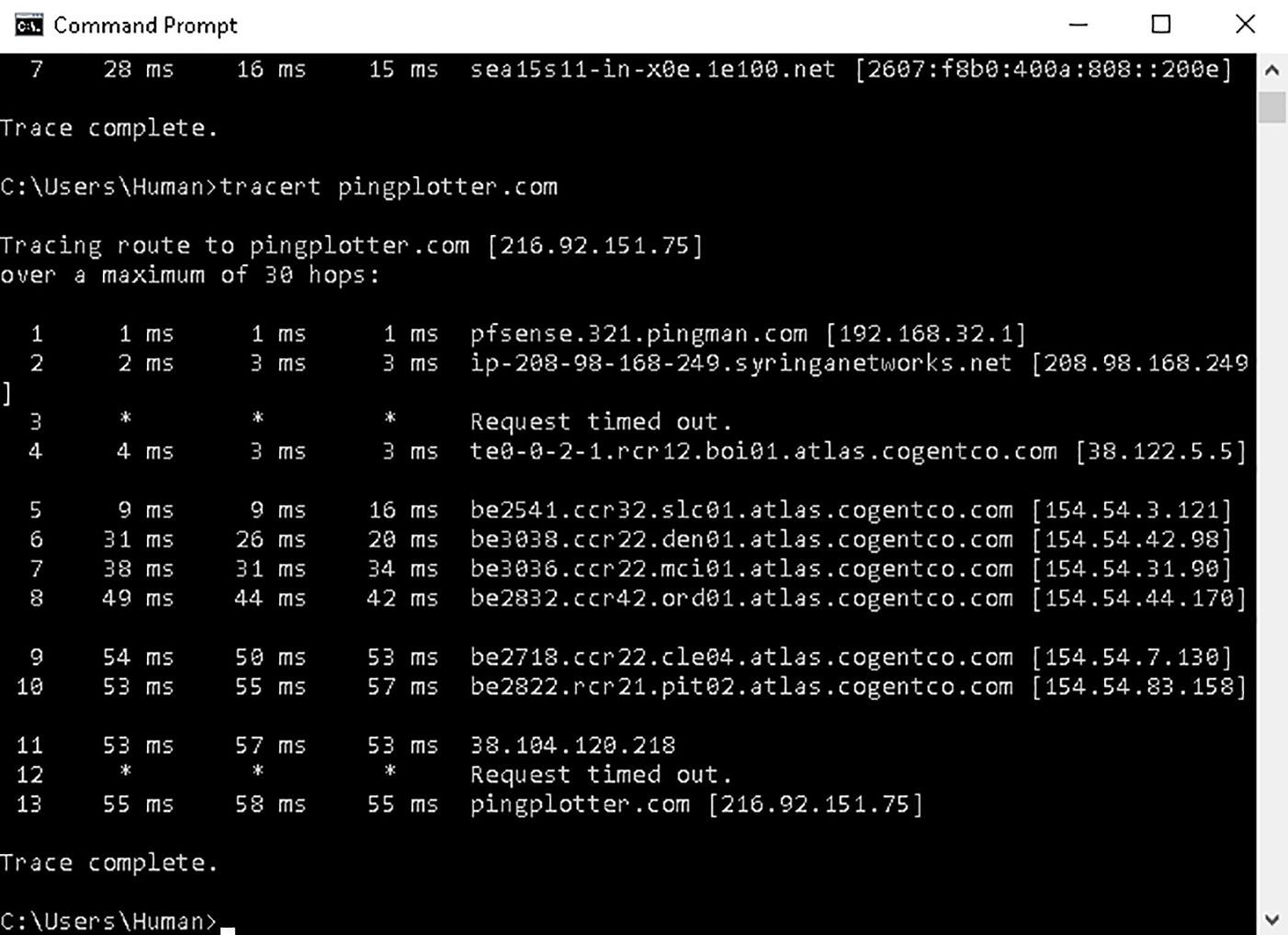
Sure, the data's correct, but good luck using it on the fly...
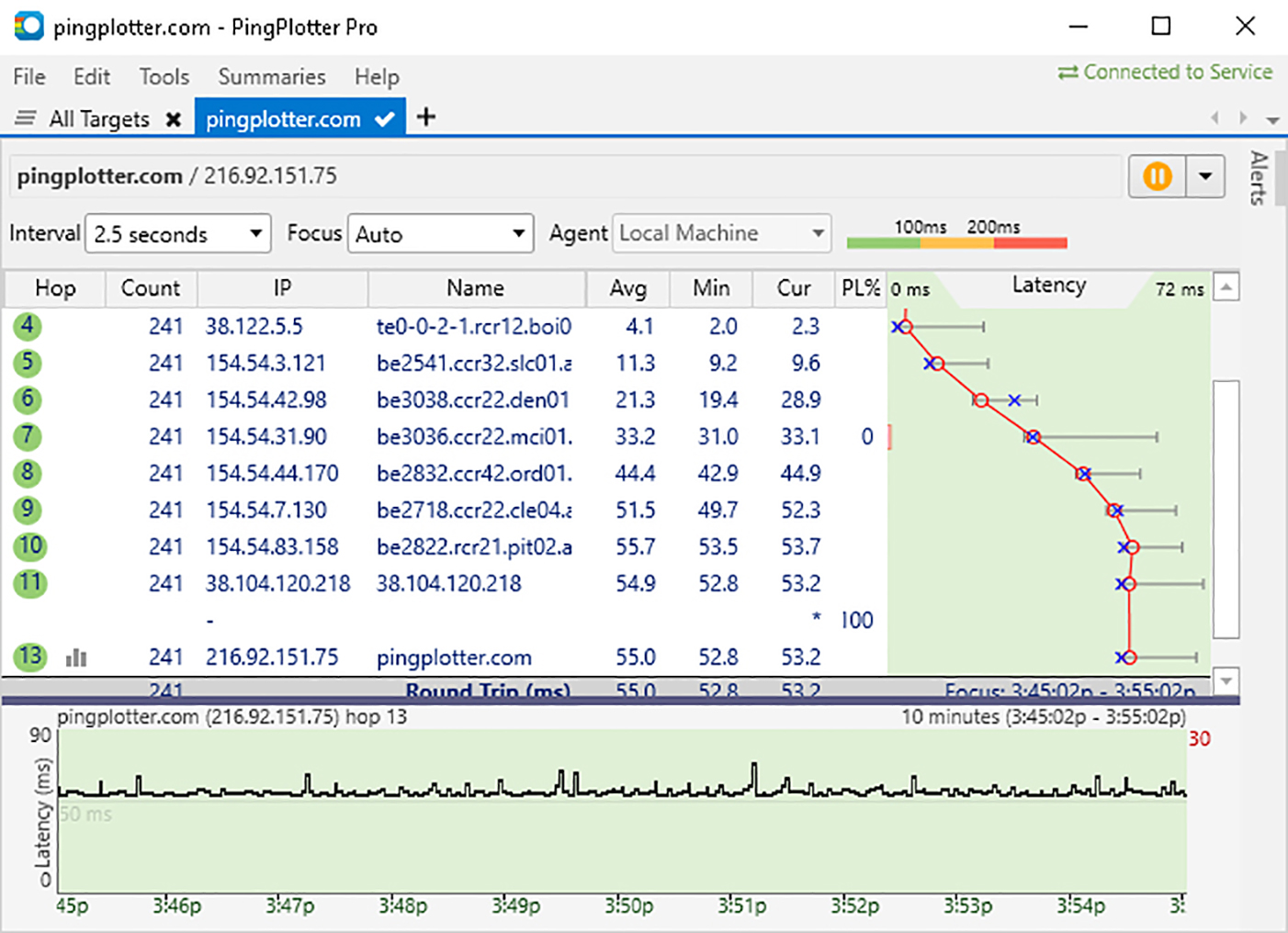
The same data, but ready to use the second you need.
This is a trace conducted through both traceroute and PingPlotter at the same time. Both collected the same data, but it only takes a glance at the PingPlotter screenshot to see if our network is having issues. When it comes time to actually solve a problem, you’re already a few steps ahead.
Simply the best
Ping and traceroute can tell you a lot, but they really aren’t the best tools for the job. When it comes to solving problems, monitoring performance, or just learning more about your network or someone else’s, it’s hard not reach straight for PingPlotter. It’s fast, resource-friendly, and collects important data in ways few other tools can — because who needs a ping tool when you could have PingPlotter instead?
Speaking of which, finding the best tool is just the first step in becoming the master of your domain (puns!). We have a number of handy resources to help you get the most out of your networking tool, regardless of what you use. Our wisdom hub has guides on troubleshooting best practices, identifying common network problems, and more.
Do you support remote workers?
When remote workforces have connection trouble PingPlotter Cloud helps you find the problem and get everyone back online fast.