How PingPlotter Works
If you’re relatively new to the world of troubleshooting network problems, a lot of this subject matter can seem a bit daunting at first. Fret not, though - we’ve got an analogy that should help make things click.
If you’re not new to this space (and possibly just rolled your eyes at the idea of reading through an analogy), feel free to skip to the technical details toward the bottom of this section.
Network traffic is a bit like freeway traffic
A network can operate a bit like a freeway; things are great when everyone is going the speed limit and we only have 50% of the maximum traffic that’s designed to go on that freeway. When we start to add more and more traffic, though, at some point the freeway won’t have the capacity for anymore.
Problems will start to arise as new drivers try to merge on the freeway. People that are already on the freeway will sometimes slow down and cause traffic jams. If it gets too bad, some people may give up altogether - and decide not to continue their journey.
On a freeway, this might be referred to as “congestion” - and this “congestion” happens on networks as well (in pretty much the same way). Packet loss and latency (two terms you’ll be getting very familiar with) are both symptoms of congestion - when there’s too much traffic for the network to handle.
Let's say this proverbial freeway is the one we take to get home from work every day. Let’s also say (for this example) that between work and home there are 15 off-ramps with turnaround points off of the freeway. Let's also say that we’ve got a team of 15 people, each with their own car, ready to do whatever we ask of them (again, for the sake of this example. Stick with us here).
If we want to find out the conditions on the freeway for our drive home from work, we could send out 15 cars, and assign each driver to one of those 15 off-ramps. The instructions for each driver are the same: get you your assigned off-ramp, turn around, and come back. Then we’ll measure the time it takes each car to get from us, to their off-ramp, and then back to us.
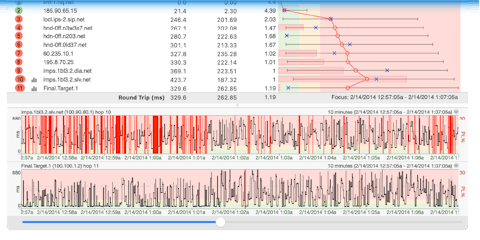
The most important car is the one that goes all the way to your target (or home) - that 15th car. If it makes it there and back again in the expected time, then we know that the traffic on the freeway is running pretty well.
If that 15th car takes longer than expected (or if it never returns), then we can look at the results for the other off-ramps to find a likely place where problems could be occurring. Maybe all the cars through off-ramp #9 had no problems (and returned quickly) - but the cars that went through off-ramp #10 (and beyond) started getting delays (or didn’t return). From this, we can see that there is some kind of problem happening past off-ramp #9.
PingPlotter operates *very* similar to this; it sends out data packets that go all the way to a target destination (as well as each stop in between) and measures the amount of time it takes to get there. It also measures how often a packet (or a router) gives up. This information can be used to figure out where (and when) problems are occurring.
For the sake of taking this analogy too far, let's look at one other scenario. Let’s say that off-ramp #5 is in a small town where the police are of a disposition to pull people over for no reason (this is all theoretical, of course - we would never imply that any police actually do this). Each car that we send to off-ramp #5 have to pass by these police officers, and 20% of the time, they get pulled over. Another 15% of the time, there’s someone else pulled over there, and our car has to wait while that car moves off the road. Meanwhile, traffic is whizzing by on the freeway, unrestricted.
This situation can happen on a network with PingPlotter as well - where the packets going to hop 5 might get waylaid by some local rules and show packet loss, latency, and jitter that are not being experienced by packets destined for other places.
Technically speaking…
At its heart, PingPlotter is a traceroute utility. It's souped-up and on steroids, but the basic data it collects is based on the theory of traceroute.
A ping packet is an IP packet requesting that a copy of its contents be echoed back to the sender. When you "ping" a site, you send over an echo request and that site responds back that it received it.
One of the parameters on a ping packet is something called "Time to live" (TTL) - which is an IP header field designed to keep packets from running in loops (essentially forever) throughout a network (this can happen when there is a route change, and the routers involved don't all know the same information as new information is being replicated out). Initially, it's usually set to somewhere between 64 and 255 and is reduced by 1 every time it passes through a server. If the TTL should ever reach zero, the packet has expired, and the router that it's passing through will send it back to the source.
Traceroute plays with this TTL number on outgoing packets. It first sends out a packet with a TTL of 1. The first router that sees this and decrements it to 0, and then sends it back. It also sends back its own IP address with the packet, and DNS is used to do a lookup for an actual domain name.
Next, traceroute sends out a packet with a TTL of 2 so it can find out what the next computer in the route is. Then it sends out a packet with a TTL of 3. This process is repeated until the final destination is reached. At that point, you know the entire path the packet has traversed to reach the destination computer/router. Each server/router in this chain is called a hop.
This method can help us determine the route a packet takes, but if we time each of these packets, we also know how long it takes for a packet to make it from our source PC, to that router, and then back again. This is called latency.
The last hop in a (successful) traceroute is actually the round-trip time to the destination server. This is an important concept to understand. You don't add up all the times between you and the destination host - as that time has already been added. The time to the last hop in the chain is exactly the same as is if you'd used a ping utility to that host. So a traceroute utility is actually two utilities - ping AND traceroute.
PingPlotter speeds up this process by sending out packets to the first 35 servers in the route all at the same time. This makes a HUGE difference in overall speed. It also means that the network conditions for each hop are very similar - so the numbers are better compared.