Interpreting Results - Bad Hardware
Scenario: External customer has problems using your network resources.
A customer (not inside your network) has problems losing connecting to services inside your network. In this scenario, you are acting as a service provider for some network service. This might be provided via HTTP, or possibly through something like Citrix or Windows Terminal services.
Your customer (possibly employees of your company, or maybe subscribers of your service if you’re an ASP-based service) is complaining of frequent disconnects, and possibly slow performance sometimes. How do you troubleshoot this kind of a problem? Where is the problem; at the entry point to your network, in the customer network, or possibly in one of the providers in between?
One way to pinpoint the problem is to have your customer run PingPlotter against your service. They can easily download PingPlotter, capture data, and then either analyze that data themselves, or email the data back for you to analyze. This information can be used to pinpoint which hop (or router) in the chain is adding latency or losing packets that might be causing problems back to your ASP.
Analysis:
Here’s an example extracted from a real-world customer situation. We’ll walk through some of the symptoms, collected data, then analysis and how we came to the proper conclusion.
Our ASP (we’ll call the ASP "CitServeCo" - a totally fictitious company) is accessed via Citrix, which is relatively sensitive to high latency and packet loss. The customer (who uses financial applications served by CitServeCo) was frustrated by disconnects during the day, which lasted anywhere from a few seconds to a minute or two, interrupting their ability to do business.
The customer will almost certainly blame CitServeCo initially for a problem like this – but we need a way to determine where the problem is being caused, and help the customer solve the problem. Any reliable ASP will get numerous complaints like this – that they *know* are the fault of something beyond their control (like the customer’s cable connection, or similar). Most ASPs will attest to the fact that customer connections are a prime source of network problems, but we can’t just tell the customer "It’s your problem."
When the customer contacted CitServeCo, they suggested that they download PingPlotter, install it onto the workstation they normally work with, and configure it to monitor the Citrix server inside CitServeCo’s network.
If a disconnect or slowdown occurs in Citrix, we suggest to the customer that the right-click on the lower “time-graph” in PingPlotter and create a comment at the point that the problem occurred. This correlates real world symptoms with the collected PingPlotter data (a crucial part of the troubleshooting process).
A day of collecting data resulted in only a single disconnect, and the customer dutifully recorded that for us. They then sent us the saved data for analysis. Because PingPlotter data is already compressed, there is no need to .zip up the file, making it easier to send data.
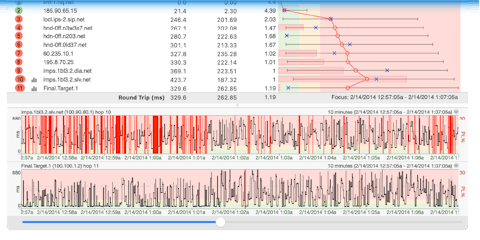
Here is the result of that day.
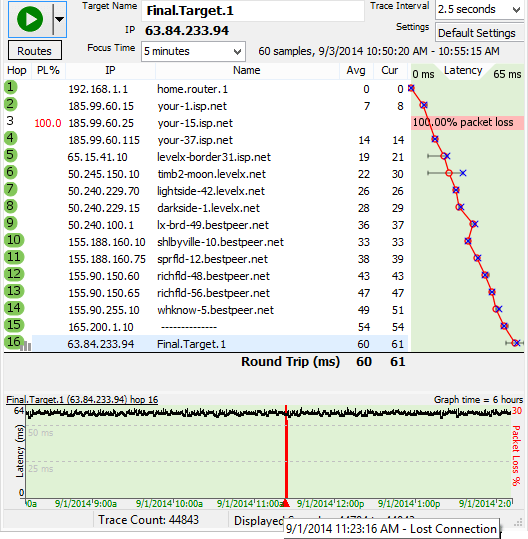
Notice the packet loss in the timeline graph at 11:23 am. This corresponds with a note from the customer in the data file that shows the disconnect happens. We decide we want to take a closer look. To do this, we set the “Focus Time” to 5 minutes, double-clicked on the red point in the time-graph, and then reset the time-graph period to 5 minutes instead of 6 hours.
Wow. A big outage. If no packets were getting through, we’re definitely going to see problems. Where did that loss occur? If we look at the upper graph, we see that we have consistent packet loss across *all* the routers (double-clicking on the lower graph focused the upper graph on the period we were interested in). The packet loss was similar, but let’s have a look at the actual lost packets. To do this, double-click on a router in the upper graph to show a time graph for that router.
It looks like hop 1 lost just as many packets as hop 16. Since every piece of data needs to go through hop 1 to get to any of the other hops, a blockage there will look just like this. It looks like we’ve found a likely culprit – the router at hop 1, or possibly anything between the computer collecting data and hop 1. This might be as simple as a network cable, or it might be a significant amount of network equipment. We don’t know until we check with the customer to find out what’s here.
We asked the customer what kind of network hardware they have in place. While they were collecting this information for us, we had them continue to monitor their connection.
It turns out that all the computers at this location are hooked up to a "SOHO" router. This SOHO router is, in turn, connected to a cable modem provided by their ISP. From their ISP, the customer is uncertain as to the network configuration. We see some of this in the PingPlotter graph – a list of routers that are participating in sending data.
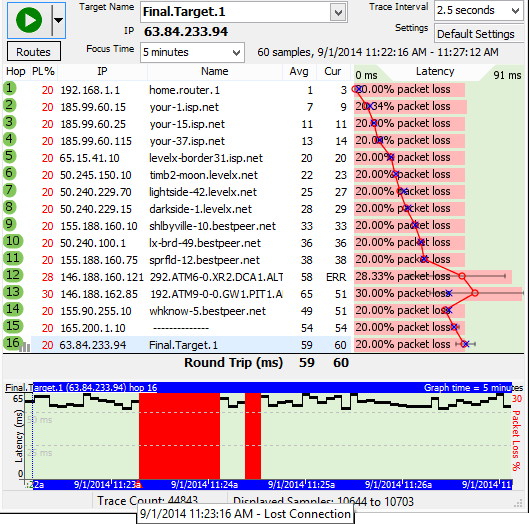
The customer was uncertain as to what the individual pieces of hardware reported in as, so we had them continue to monitor, but asked that they cycle the power for the devices if they had a disconnection problem. Several days later, they had an opportunity to do this, and captured the experience in PingPlotter.
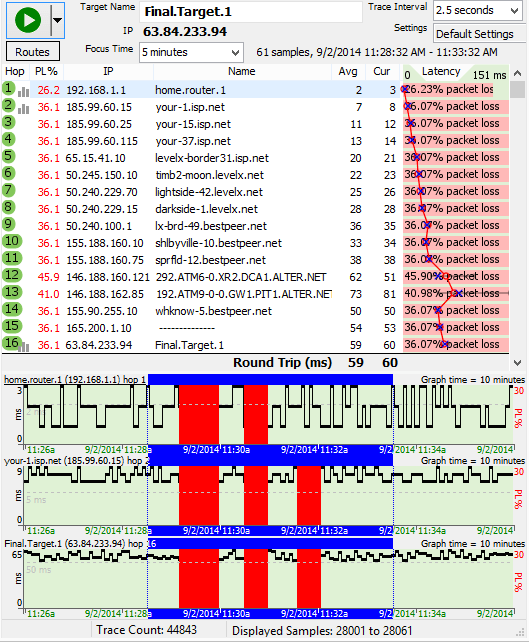
In this instance, the customer had a disconnect, and then rebooted their SOHO and their cable modem. Notice how hop 1 stays working through the reboot of their cable modem, but not through the reboot of the SOHO. So this must be the SOHO. Also, notice during the disconnect, hop 1 was non-responsive. This indicates the problem was similar to having the SOHO powered off.
Maybe there was a bad power supply on the SOHO, or maybe a bad network cable someplace? The customer replaced the network cables, and the problem persisted. They then replaced the SOHO router and the problem was solved.
It’s not every case where the problem is so “in our control” as it was in this one. Sometimes, the problem requires talking an ISP into replacing some piece of their hardware, or replacing an ISP alltogether. PingPlotter can be just as effective locating the outages, packet loss, or latency on ISP equipment, though – it’s can sometimes just be harder to fix those problems.