A Beginner's Guide To Anomaly Detection and its Role in the Network

From network intrusion detection to customer behavior analysis, anomaly detection is a crucial step in a business’s data mining process. Anomaly detection, also known as outlier detection, identifies data objects or patterns that deviate from a dataset’s normal behavior.
Regardless of whether it’s used for cybersecurity, marketing, or medical purposes, anomaly detection is governed by two basic principles:
- Anomalies are rare occurrences
- The anomaly presents itself in a manner that significantly deviates from expectations
Anomaly detection techniques can identify critical issues like website hacks, bank or insurance frauds, technical bugs, network errors, structural malfunctions, and business-altering changes in customer behavior.
What is an Anomaly?
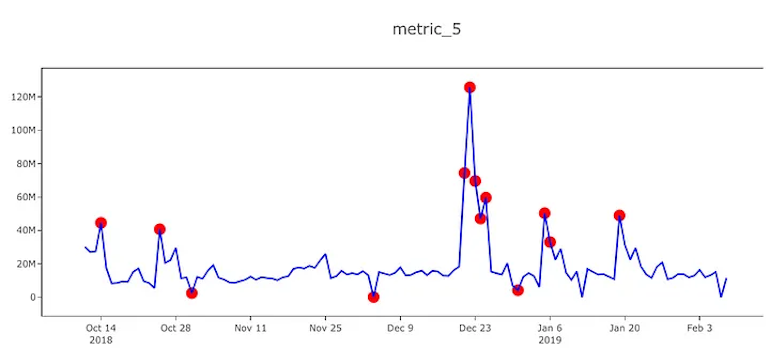
An ‘anomaly’ or ‘outlier’ refers to any identifiable value that significantly deviates from typical patterns of behavior. This could be an event, item, or observation that doesn’t correspond to what we’d consider the norm. In the image below, the red dots represent anomalies.
Thanks to data collection, data analytics, and data virtualization software, we have increased control and visibility over all of our internal business operations. With the ability to accrue millions of metrics from our business’ most hidden corners, we can create substantial datasets to successfully manage the performance of our business activities on a large scale.
Within these datasets lie data patterns and standards that illuminate typical behavioral baselines. These data patterns reassuringly indicate “business as usual”. Any value within a dataset that deviates significantly from this data pattern or standard would be considered an anomaly, which often points to a critical or unexpected issue.
For example, in credit card fraud detection, an anomaly might be a transaction that doesn’t fit with the user’s previous purchasing behavior. In network security, a traffic anomaly might point to an intrusion attempt.
So, Are Anomalies Always Bad?
Anomaly detection is often associated with use cases like intrusion/fraud detection and network troubleshooting, so it’s unsurprising that businesses tend to focus on detecting negative anomalies. However, anomalies can be positive, too.
Say the video you posted on social media suddenly goes viral, or your PPC ad does a lot better than expected. Although this data will skew your results and present themselves as anomalies, they show that you’re doing something right!
Types of Anomalies
Generally, an anomaly will fall into three different categories: global outliers, contextual outliers, and collective outliers. To get the most value out of your anomaly presentations, it’s important that you understand the differences between each type.
Global Outliers
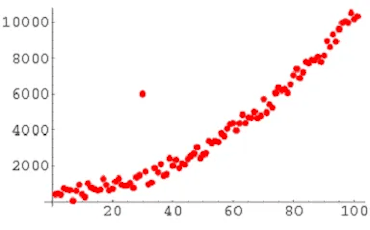
A global outlier (also known as a point anomaly) is a value that exists far outside of the data set it exists within. Global outliers are the simplest and most easily identifiable type of anomaly, as you can see from the image below. They often point to things like hacking or fraud instances.
Contextual Outliers
A contextual outlier is a data point that significantly differs from the rest of the data points in the same context. This type of outlier is commonly found in time-series data as the ‘context’ is usually temporal (time-series data presents a collection of observations over specific intervals of time).
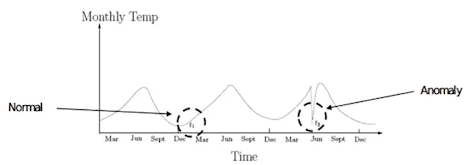
Subsequently, a data point that appears to be abnormal in one context may not be abnormal in another.
Let’s use a simple example here. An established ecommerce store selling fancy dress costumes may have steady sales throughout the year up until October, at which point they experience a huge spike in sales. Now, even though this sales spike is abnormal in the context of yearly sales, it isn’t an anomaly in the context of seasonal sales.
Why? Because data from previous years will undoubtedly show that sales always surge in October as people prepare for Halloween. Thus, this spike would still be regarded as ‘the norm’ because it’s a pattern of behavior that aligns with expectations.
Now imagine if there was no spike in sales during October. This would be a worrying anomaly for the business as it deviates from standard patterns of behavior.
Monitoring data patterns and contextual outliers is often used to aid the success of demand forecasting in retail.
Collective Outliers
A subset of data points that deviate significantly from the dataset - but when looked at individually are not anomalous on either a global or contextual level - are considered to be collective outliers.
For example, a business with an average expenditure of $500 on weekly overhead costs wouldn’t consider a one-off $600 average to be an anomaly. However, if this was to continue over several weeks, an anomaly may be detected.
Anomaly Detection Use Cases
While cybersecurity remains a popular use case for anomaly detection, its significance has grown beyond financial and IT safety. Industries from healthcare to ecommerce retail and games development are using anomaly detection to improve business operations and product quality.
Here are just a few use cases of anomaly detection.
Fraud Detection
Commonly used to prevent instances of credit card and insurance fraud, graph-based anomaly detection (GBAD) is used to analyze connectivity patterns and detect suspicious behavior. Online banking fraud can also be mitigated by ML systems through the use of behavioral metrics that monitor real-time spending and flag any behavior that doesn’t correlate with typical spending patterns.
Anomaly detection plays such a critical role in cybersecurity strategies that cloud computing platforms, such as Microsoft Azure, provide anomaly detection services across all of their Azure instance types.
Network Security
Intrusion detection systems (IDS) and network behavior anomaly detection (NBAD) technology play a key role in network security. Its goal is to detect hidden threats and vulnerabilities within the network infrastructure which, if discovered, are passed on to network security professionals.
Network behavior anomaly detection analyzes traffic flow patterns, packet signatures, network performance data, and more in a bid to uncover hidden threats and suspicious network behavior. It is critical that network monitoring is conducted on a continuous basis to mitigate the impact of compromising issues such as infections, data leaks, network intrusions, and other types of cyberattacks.
Common use cases of a network security anomaly detection system include:
- Link failure detection
- Ransomware detection
- Suspicious device detection
- DDoS attack detection
- Suspicious packet signature detection
- Dictionary attack detection
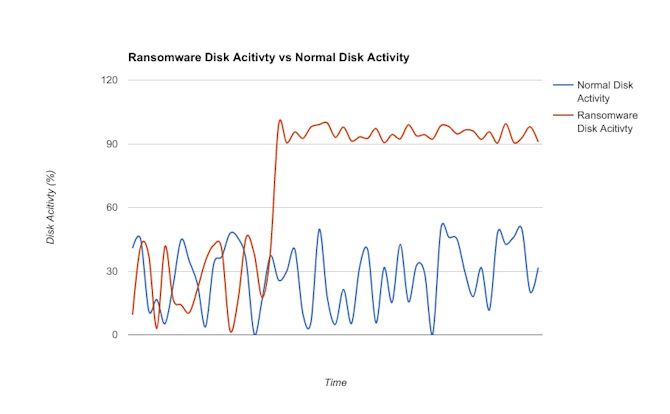
Application Performance and Testing
Anomaly detection has become a foundational part of any software release life cycle. Rather than react to issues after they’re reported by customers, developers can use machine learning algorithms to monitor performance metrics against the norm, enabling the swift detection and resolution of bugs, glitches, and other issues.
The same goes for websites. Websites can often fall prey to technical glitches and bugs that, if they go unnoticed, can wreak havoc on performance metrics. A real-life example of this happening is when Argos failed to notice a pricing glitch, which ultimately led to a site crash, angry customers, and lost revenue.
Troubleshooting your customer’s user experience should be a task you perform continuously. Anomaly detection can identify hard-to-spot website and application outliers, mitigating the reputational and financial impact of glitches, bugs, and cybersecurity attacks.
It’s such a pressing issue that if you’re a web design company, it’s worth including any anomaly detection services you deliver in your web design proposal sample template.
Social Network Anomalies
Let’s say one of a business’s affiliate marketing ideas is to partner with an influencer and host a promotion or giveaway. It’s essential that the business ensures that the influencer - and their followers - aren’t online fraudsters, spammers, fake users, predators, etc. Anomaly detection systems can assist with the vetting process by flagging suspicious behavior, thus reducing the likelihood of partnering with dangerous online persons.
Other use cases include stock trading, industrial damage, medical imaging, and gaming solutions use cases.
Anomaly Detection and Machine Learning
Back when we only had access to a handful of basic metrics, businesses could perform anomaly detection manually. But, with the explosion of big data and the increasing smarts of cybercriminals, we not only have millions of metrics at our fingertips - we also have new online threats to contend with.
Network traffic is also growing at an astronomical rate - mobile traffic alone is set to exceed 300EB per month in 2026.
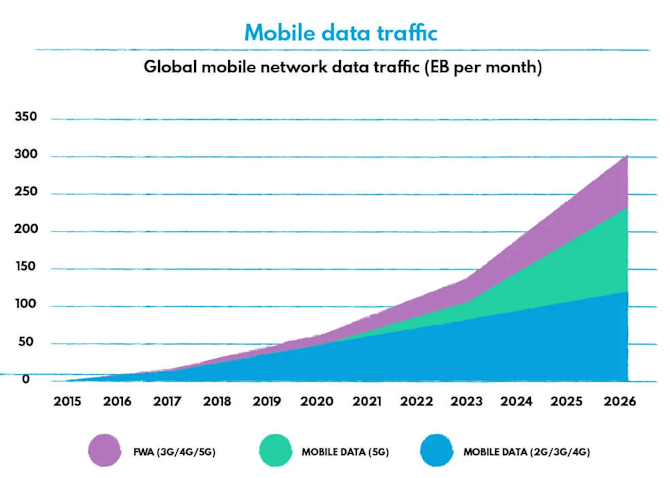
Rather than handle it manually (and risk burnout, human error, and a host of other issues), businesses are turning to machine learning to enhance their network security measures and the value of their business analytics.
Machine learning (ML) has accelerated the speed and accuracy of our anomaly detection initiatives. When combined with powerful integrations (like the Databricks and Amazon Sagemaker tutorial), we are able to build, train, and deploy machine learning models that assist us in establishing norms and detecting anomalies in diverse environments.
Unsupervised ML systems can even identify data normalities and abnormalities within unlabelled and unstructured data, all without prior knowledge or human intervention.
However, there is the challenge of false positives to contend with, which is an issue that befalls humans and ML systems alike. Noise within the network can hide outliers, obscure distinctions, and result in false positives. An example of a false positive might be if a network update unexpectedly transferred a large volume of data to an endpoint.
Anomaly Detection Machine Learning Methods
Though not an extensive list, here are the most common machine learning methods used by businesses today.
Density-Based Anomaly Detection
Using the k-nearest neighbor (k-NN) algorithm (which is a rudimentary, non-parametric, and supervised ML technique), density-based anomaly detection classifies data based on distance metrics like Euclidean, Hamming, or Minkowski distance.
This approach is governed by the assumption that normal data points occur in dense environments, which means that anomalies are defined as those that appear far away from these environments. Put simply, if a data point is surrounded by other data points, it is assumed to be normal.
The similarity between singular data points is therefore measured through their distance from each other.
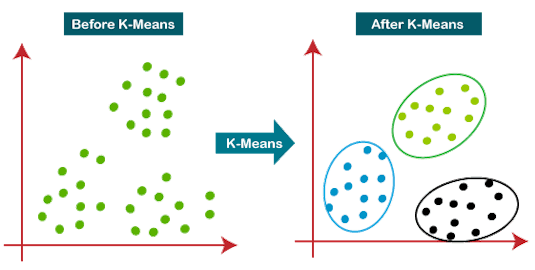
Clustering-Based Anomaly Detection
Possibly the most popular unsupervised ML method is clustering-based anomaly detection. Clustering uses a K-means algorithm to create groups of similar data points within complex datasets. Any data points that don’t ‘fit’ into any of the data groups are considered to be anomalies.
Support Vector Machine-Based Anomaly Detection
A support vector machine (SVM) is generally used in supervised anomaly detection tasks and learns softer boundaries than many of the other techniques. All of the data captured within the soft boundary is classified as normal, whereas observations that fall outside of the boundary are identified as outliers.
There are lots of different algorithms and approaches that you can use depending on the size, complexity, and type of the dataset in question. One of the main things to consider is the type of training and test data you use or, in other words, whether you’re performing unsupervised, supervised, or semi-supervised anomaly detection.
What is Supervised, Unsupervised, and Semi-Supervised Anomaly Detection?
We’ve mentioned the above terms a couple of times in this article, but what exactly do they mean?
Supervised Anomaly Detection
Supervised machine learning algorithms are trained via human intervention. With the help of data labeling software, humans are able to feed supervised ML systems datasets that contain well-known examples of both normal data patterns and anomalies. Then, when presented with ‘real’ data, the algorithm categorizes this data based on the human-fed examples.
Supervised anomaly detection works best with unbalanced classes and common outliers, like solving common network problems. However, because the trained data fed to the algorithm is pre-labeled and categorized, supervised systems can only categorize new data if they’ve already seen a pre-learned example.
This makes supervised methods unsuitable for the detection of unknown outliers.
Unsupervised Anomaly Detection
Unsupervised algorithms establish a baseline for normal behavior in unlabelled test sets of data based on the intrinsic characteristics of each value rather than any pre-determined examples of normalcy. This enables unsupervised machine algorithms to detect previously unseen anomalies, like complex network problems.
Semi-Supervised Anomaly Detection
Semi-supervised detection provides ML systems with a labeled training data set devoid of anomalies which they use to establish a model for normal behavior. The working assumption of semi-supervised methods is that if the algorithm knows inherently what a normal dataset looks like, it will be able to detect any anomalies that crop up.

Summary
Anomaly detection improves business operations by increasing data visibility and visualization. It enables us to stay on top of trouble with automated alerts, delivering the real-time critical anomaly information that propels pivotal, time-sensitive business decisions. It also presents us with the data patterns and norms that drive our business processes and inform our future goals.
Regardless of whether you’re using it for cybersecurity, troubleshooting, marketing, or medical practice, machine learning and AI-powered anomaly detection is a key tool for maximizing the actionability of your data.

Pohan Lin
Senior Web Marketing and Localizations Manager, Databricks
Pohan Lin is the Senior Web Marketing and Localizations Manager at Databricks. Databricks Elasticsearch is a global Data and AI provider connecting the features of data warehouses and data lakes to create lakehouse architecture. With over 18 years of experience in web marketing, online SaaS business, and ecommerce growth. Pohan is passionate about innovation and is dedicated to communicating the significant impact data has in marketing. Pohan Lin also published articles for domains such as SME-News.