Is PingPlotter Safe?

Between bandwidth concerns and bad actors, is ping more trouble than it’s worth? We used PingPlotter to find out.
There’s a modern saying:
If you want to freak out, just type your symptoms into Google.
It doesn’t take much to go from ‘my throat itches’ to ‘I HAVE ALL DISEASES PUT ME IN THE BUBBLE!’
Network forums can be the same way. You start looking for advice on how to ping a server, then all the sudden a tinfoil hat-wielding maniac is waving his hands in the air screaming how you’re seconds away from breaking every PC in existence.
Ok. Maybe it’s not that bad.
Still, it’s hard to parse the fact from fiction when you have people talking about pings of death, denial-of-service attacks, and general chaos breaking loose the moment you ask about pinging a server.
So how much of it is true? Does pinging too much make things worse? Can a tool like PingPlotter do more harm than good?
Today, we find out!
We rigged up PingPlotter to show, once and for all, how much harm ping can really cause. And the results are...well, you’ll see.
ICMP, yeah you know me
But first? Some context.
The biggest concern around pinging a network often has to do less with the act and more with the protocol used — ICMP.
The Internet Control Message Protocol is one of the primary methods network hosts use to exchange important diagnostic information. ICMP carries all sorts of info, from redirect instructions to timestamps for time synchronization between devices.
What ICMP is probably best known for, however, is echo requests. This is pretty much what it sounds like. One device sends out an ICMP packet to another, telling the recipient to send a reply confirming it received the request. The recipient then responds with a new ICMP packet, the echo reply, confirming the request.
That’s what ping actually is. One machine is like, “u up,” and the other is like, “mhm 🍆🍑?”
What makes ICMP so special? For starters, it’s lightweight. Because of the streamlined nature of the payload, ICMP frames are typically 64 bytes in length — the smallest Ethernet will allow. This lets devices communicate with incredibly low bandwidth overhead.
Next, ICMP functions on a separate OSI model layer than other packets. Since ICMP operates on layer 3, it is traditionally unimpeded by data transmission. This allows devices to communicate regardless of what else is happening in the pipeline (most of the time).
So, if ICMP is so light and fast, what’s the problem?
Well, as it turns out, you can make anything into a weapon if you throw it hard enough...
Haters gonna hate
A lot of trepidation around ICMP comes from its historical ease of abuse. ICMP has been used to do some pretty gnarly stuff, from compromising security to completely shutting down servers. While most of these issues are relics of a wild-er west of networking, the stigma lingers.
The most infamous problem is the "ping of death.” True to its name, the ping of death utilizes a flaw in how hosts resolve ICMP requests larger than the Internet Protocol is built to handle. By making a packet larger than 65,535 bytes (the maximum size allowed by IP), bad apples can force a device to crash while trying to reassemble it.
Fortunately, enough precautions exist today that prevent pings of death from taking down a host. Modern firewalls can be set to check incoming packet fragments and confirm the completed packet falls within protocol parameters. In addition, a device’s memory buffer can be set to larger than IP allows, preventing pings of death from causing a buffer overflow (which is what causes the device crash in the first place).
In addition, due to the nature of how a ping of death actually operates, it does not explicitly require the use of ICMP — any protocol can generate a packet larger than IP allows. In that sense, ICMP isn’t really to blame for pings of death at all.
Another issue is security. Remember how we mentioned ICMP operates on a different OSI layer? This can circumvent firewalls and other protections focused on filtering traditional data. While you may have specific ports open or closed to regulate traffic, ICMP has its own lane. Leaving it open can allow enterprising individuals access to information you’d much rather they not have.
Much like with the ping of death, the modern security concern has become a bit overblown. For the last several years, many network admins have been blocking all ICMP traffic by default to prevent abuse using the protocol. However, the truth is many of these precautions are far too excessive and come at the cost of legitimate network functionality. ICMP exists for a reason and blocking it off completely undermines some incredibly important features.
And then there are the practical issues. When using a tool like PingPlotter, you have the power to send ping packets like nobody’s business to hundreds, if not thousands, of devices. Even with such a small packet size, the sheer volume of ICMP echo requests cranked out by PingPlotter can’t be doing a network any favors, right?
That’s a great question, and definitely a valid concern. So much so, we wanted to actually prove whether or not you really could use PingPlotter to do some damage.
Grab your safety goggles — it’s science time!
I mean, what could possibly go wrong?
So, how do we go about testing PingPlotter’s threat level?
Let’s take a step back. In general, we’re concerned with two issues. First, we want to know if PingPlotter can ping a host so much it triggers DoS/DDoS protections and starts hard-rejecting ICMP packets or kills the server flat-out (a concern many have). Second, we want to understand how factors like PingPlotter’s bandwidth usage impact network performance.
That can only mean one thing — it’s time to find an endpoint and ping the crap out of it.
...huh?
Before we begin, it can help to understand how PingPlotter actually tests a network. Luckily, we have a great article covering just that. It should give you a good frame of reference for what we’re about to do.
The idea is simple. Using ten instances of PingPlotter installed across ten devices, we can trace the full route to a fixed endpoint like normal. However, instead of conducting one trace, we’d do 2,500 — 250 concurrent traces per device. Otherwise, it’s business as usual. We’d send out default ICMP ping packets to every hop in our route every 2.5 seconds and let the traces run for one hour, giving everything a decent chance to fail.
There are a few reasons to use this setup.
First, it allows us to correct for specific variables related to hardware. PingPlotter can trace far more than 250 routes concurrently, but we want to be absolutely sure hardware isn’t going to impact the frequency of pings.
Second, it allows us to work out any route hiccups in the first few hops. Our internal network results should be consistent between every device, so any outlying results can be confidently excluded.
When thinking about what trace target makes an enticing guinea pig, there’s only one right answer — pingplotter.com. We’re always confident in PingPlotter’s safety, and now it’s time to prove it by putting our own website on the line. Also, just in case we’ve somehow been wrong this whole time, it’s better to break ourselves than someone else.
However, we want to know more than just whether or not you can break a thing using PingPlotter. We also want to better understand how our software impacts everyone down the line. That’s why we also decided to reach out to both our ISP and our hosting service to get their take on our experiment.
Our ISP really didn’t have any issues with what we were planning. There was some concern about bandwidth saturation for us (it wouldn’t matter to them), but the idea of the experiment didn’t raise any serious discussion.
It was the same with our web host. The idea of sending so many packets to their server with such sustained frequency didn’t even faze them. The only advice they gave was to start out “slow”: start with 1,000 traces, then ramp it up once we were confident in the stability. Otherwise, they were game to have us go nuts.
While the advice of our host to start slow is well-intentioned, it flies in the face of everything we’re hoping to do.
So we’re gonna ignore it.
Yep. 2,500 traces fired straight at pingplotter.com’s dome all at once. Let’s go!
Start your packet engines!
After hitting Start, PingPlotter began firing out packets as normal, and then...nothing. Packets flew, PingPlotter chugged along, and no one seemed to be the wiser. No phone calls, no emails, no busted website.
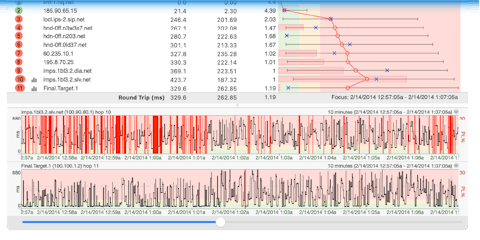
When we take a look at our network performance results over the hour we spent bombarding our host, it’s clear that, even with our quantity of traces, the impact was negligible.

Let’s start with the basics: latency and packet loss. Taking the averages among all of our traces, we see little to be alarmed about. The average latency high of 53.7 ms and low of 53.3 ms shows not only did we experience great latency throughout, but our connection was consistent. While our packet loss was higher than we’d normally like to see (and there’s a good explanation below), we’re still hovering between an average high of 3.4% and low of .85%.
In short: Our ridiculous pinging had no adverse effect on our connection quality.

What about bandwidth usage? Once again, things are looking good. Over one hour of pinging, we managed to send 2.68 GB of ICMP data, which equates to approx. 5.93 Mbps. That might sound like a lot but remember: At no point was our network strained to the point of compromising performance. Had we seen symptoms like bandwidth saturation in our latency results, we could have made an argument that maybe we were pinging too much.
But we didn’t. And remember, this network was still in normal use while we were tracing. Whatever we were doing, our ping bombardment had no effect.
Speaking of which, our service providers weren’t impacted either. When we reached back out to both our ISP and our web host, neither flagged nor were notified of anything out of the ordinary. If we hadn’t contacted them, they wouldn’t have ever been the wiser.
The results of our pinging might be boring, but they represent the best possible outcome. Between our regular outgoing traffic and the PingPlotter traces, we were sending over 16,000 ICMP packets a second and nobody blinked.
If we want to break something, it’s pretty clear PingPlotter’s the wrong tool for the job.
“But what about…”
We can deduce a lot with our experiment, but it does still leave a question or two up in the air.
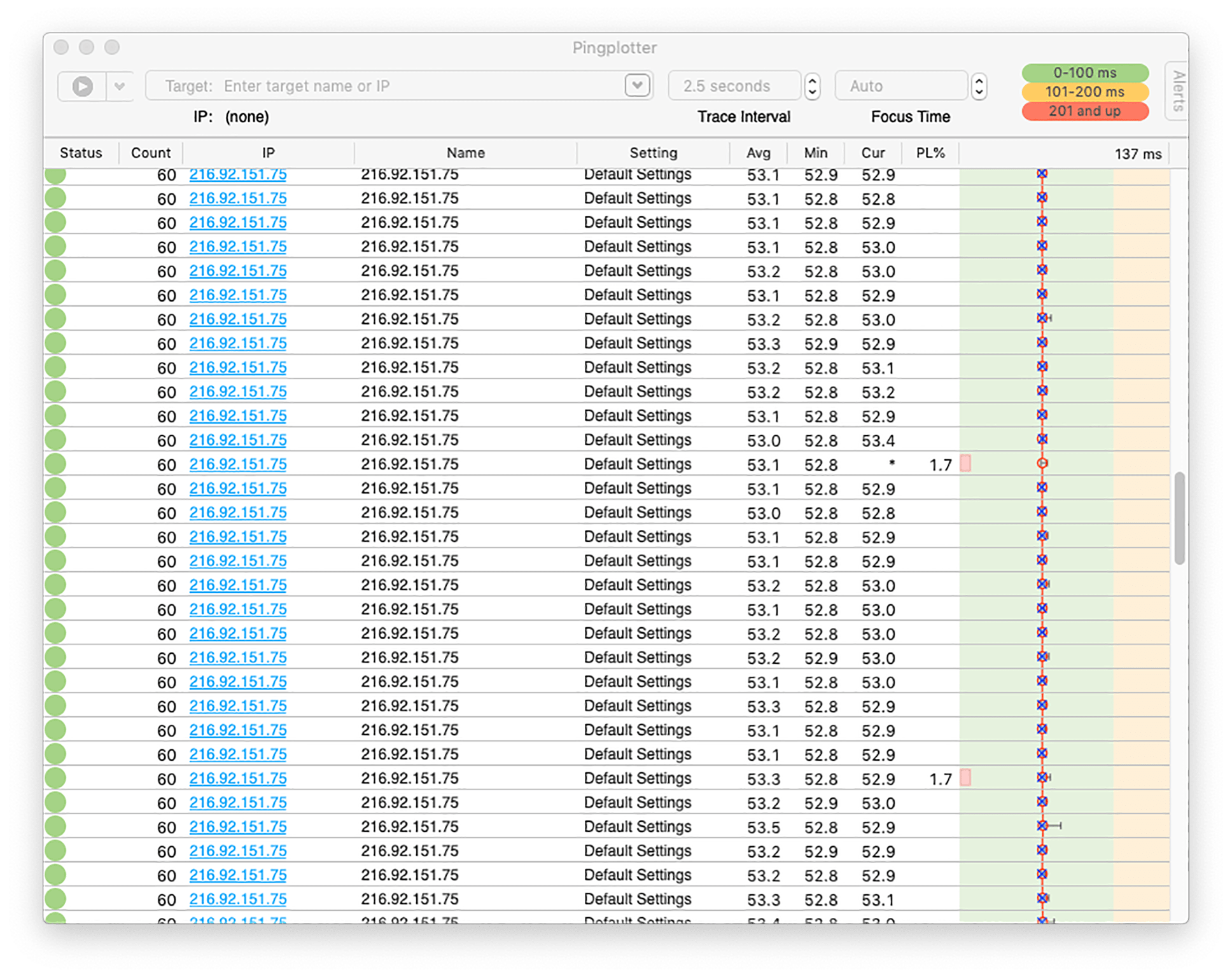
First, the packet loss. As we mentioned, we saw a packet loss percentage slightly higher than we would have liked for a ‘good’ quality connection (what’s a good connection look like? Glad you asked!). While not egregious, the packet loss still raises a question about what went wrong.
The answer? Nothing! What we’re most likely seeing is actually the routing hardware and software at work. Remember, PingPlotter technically estimates packet loss based on how many of its ICMP echo requests go unanswered. Modern network hardware will down-prioritize ICMP packets if it receives too many to handle (to prevent DoS/DDoS shenanigans). The most likely scenario is not that the connection itself was becoming unstable, but that the echo requests were periodically being ignored.
Second, the trace count. “2,500 isn’t that much,” you say, and that’s a fair argument. There are companies out there managing connections for tens of thousands of remote employees. How do things work out when you get to that scale or beyond?
Let’s keep it simple. If we were to scale our original experiment up by a factor of ten, we can extrapolate from the results that we’d be looking at about 59.3 Mbps of ICMP packets alone for our 25,000 targets — that’s starting to get up there.
However, there’s something to remember about our original experiment: We were testing the full route to every target. While it can be useful to have this data constantly coming in, it isn’t practical to conduct long-term monitoring that way. Luckily, we have another option.
If you were using traditional traceroute or MTR tools, pinging at that scale would maybe get concerning, even if you never actually encountered issues. But PingPlotter can do something those tools can’t: dynamically toggle full-route testing. PingPlotter’s Final Hop Only feature collects data on just an endpoint while conditions are normal, then switches to full-route testing when something goes wrong.
This means for the majority of our monitoring, we’d only be sending 25,000 packets during normal trace intervals, which breaks down to 10,000 packets a second. At 64 bytes per packet, our bandwidth usage would come to 5.12 Mbps. That’s right. Using Final Hop Only on ten times the traces would generate less traffic than our experiment. And to think we were worried…
Ping with confidence
So, is pinging a server dangerous?
Absolutely not.
While there may have been a time when the risks of pinging were greater, that time has since passed. The modern network landscape is built to make the most of ICMP, and many of the prior issues have been resolved or rendered moot.
If you’re concerned about breaking something, it’s nearly impossible to do so unless it’s your explicit intent. Modern routing hardware and software are built to handle anything you dish out, and if it wasn’t, pinging a server would be the least of your worries.
If you’re concerned about negatively impacting your network performance by pinging during active use, you don’t have to sweat it, either. ICMP packets are tiny and efficient. You’d need to be hellbent on causing yourself a problem to ever notice a difference.
It’s easy to freak out when you read a forum post filled with scary words and unfounded warnings. Instead, just trust the cold, hard data — if you’re looking to ping, it ain’t no thing.